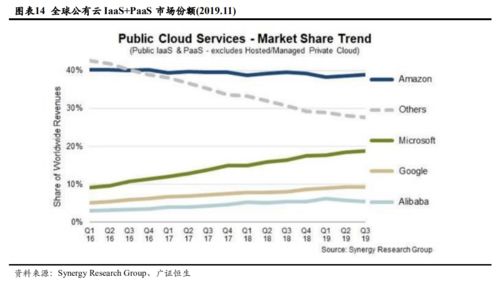
基于Flink構建全場景實時數倉 數據處理和存儲支持服務
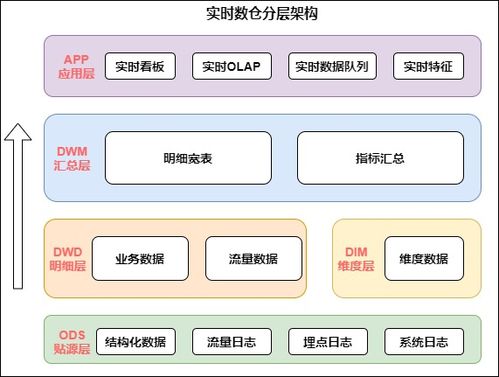
隨著大數據技術的快速發展,企業對數據實時性的需求日益增長。Flink作為一款開源的流處理框架,憑借其高吞吐、低延遲和精確一次處理語義等特性,成為構建全場景實時數倉的理想選擇。本文將探討如何基于Flink實現全場景實時數倉的數據處理和存儲支持服務,涵蓋核心架構、數據處理流程、存儲方案以及實際應用場景。
一、Flink在全場景實時數倉中的核心作用
Flink不僅支持流式數據處理,還能通過其狀態管理和事件時間處理機制,確保數據在復雜場景下的準確性和一致性。在全場景實時數倉中,Flink負責從多源(如Kafka、數據庫日志、IoT設備)實時攝入數據,進行清洗、轉換、聚合和關聯分析,最終輸出到存儲層或下游應用。其優勢包括:
- 低延遲處理:毫秒級響應,滿足實時監控和決策需求。
- 容錯性:通過檢查點機制保障數據不丟失。
- 靈活性:支持SQL、DataStream API等多種編程模式,適配不同業務場景。
二、數據處理流程與關鍵技術
構建全場景實時數倉時,數據處理流程通常包括數據攝入、實時計算和數據輸出三個階段。Flink在其中扮演核心角色:
- 數據攝入:通過Flink Connector連接Kafka、MySQL等數據源,實現增量數據同步。例如,使用CDC(Change Data Capture)技術捕獲數據庫變更,并實時流入Flink作業。
- 實時計算:Flink作業對數據進行ETL操作,如過濾無效數據、字段映射、窗口聚合(如滾動窗口、滑動窗口)和復雜事件處理(CEP)。通過狀態后端(如RocksDB)管理中間狀態,支持大規模數據持久化。
- 數據輸出:處理結果可實時寫入存儲系統(如HDFS、HBase、Elasticsearch)或消息隊列(如Kafka),供可視化工具或業務系統調用。
三、存儲支持服務的設計
全場景實時數倉的存儲層需滿足高可用、可擴展和低延遲查詢需求。Flink與多種存儲系統集成,提供靈活支持:
- OLAP存儲:如ClickHouse或Doris,用于快速多維分析,Flink可直接輸出聚合結果到這些系統。
- NoSQL數據庫:如HBase或Cassandra,存儲明細數據,支持隨機讀寫。
- 數據湖:如Iceberg或Hudi,結合Flink實現流批一體,保障數據一致性和事務支持。
可通過Flink的Table API將數據統一抽象為表結構,簡化查詢和治理。
四、全場景應用實踐
在實際場景中,基于Flink的實時數倉已廣泛應用于電商、金融和物聯網領域:
- 電商實時推薦:實時分析用戶行為數據,通過Flink計算興趣模型,并更新推薦結果。
- 金融風控:監控交易流水,使用Flink CEP檢測異常模式,及時觸發告警。
- IoT設備監控:處理傳感器數據流,進行實時聚合和預測性維護。
這些案例展示了Flink如何助力企業實現數據驅動決策,提升業務敏捷性。
五、總結與展望
基于Flink構建全場景實時數倉,不僅解決了傳統批處理延遲高的問題,還通過流批一體架構降低了運維成本。隨著Flink與云原生、AI技術的深度融合,實時數倉將更智能、高效。企業應注重數據治理和架構優化,以充分發揮Flink的潛力,構建穩定可靠的實時數據處理生態系統。
如若轉載,請注明出處:http://www.czliufeng.cn/product/17.html
更新時間:2026-01-07 09:52:27